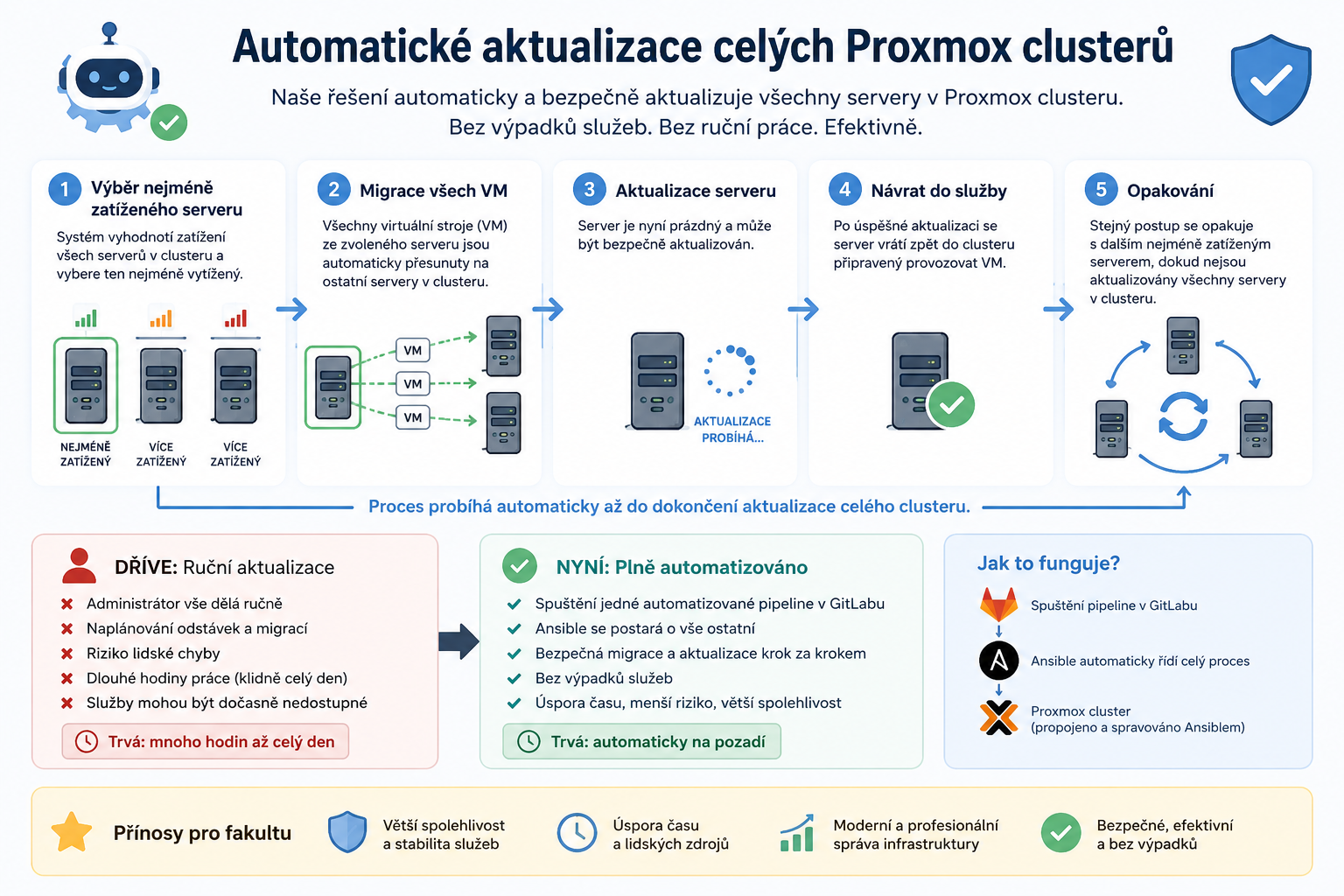
Díky bakalářské práci Ondřeje Šmehlíka jsme zapracovali pipeliny automatizovaně do Gitlabu. Díky tomu je možné naplnit směrnici NIS2 ve vyšším režimu oprávnění a řešit podobné pravidelné aktualizace zcela automaticky nezávisle na lidské ruce.

Web, který z Vás udělá lepší uživatele
Technologické novinky se budou věnovat novým technologiím na fakultě.
Díky bakalářské práci Ondřeje Šmehlíka jsme zapracovali pipeliny automatizovaně do Gitlabu. Díky tomu je možné naplnit směrnici NIS2 ve vyšším režimu oprávnění a řešit podobné pravidelné aktualizace zcela automaticky nezávisle na lidské ruce.
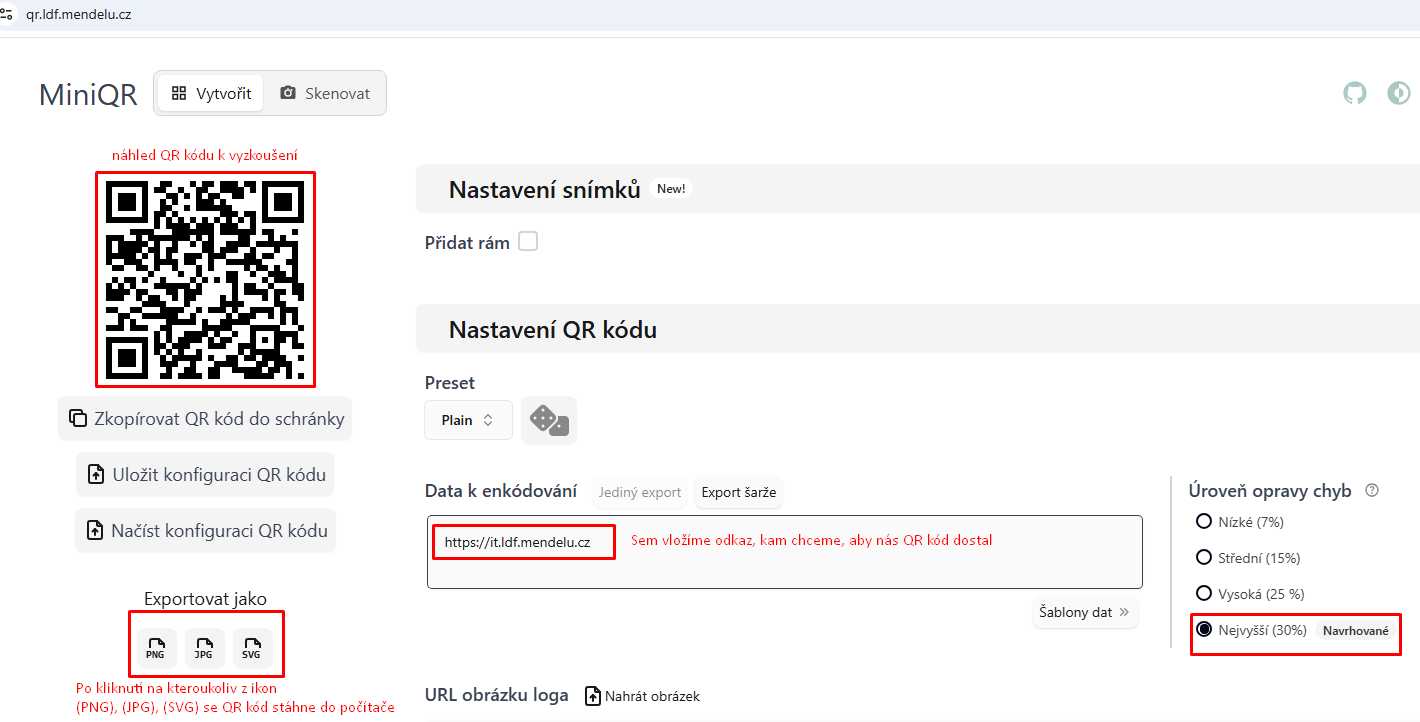
Ukážeme si rychlý návod, jak si zdarma vygenerovat QR kódy na https://qr.ldf.mendelu.cz , které vám budou fungovat i za 20 let, ale napřed zmíníme rizika, co vám hrozí, když budete používat externí poskytovatele.
Gratuluji, vyhazujete peníze oknem za něco, co můžete mít jinde zdarma. Neobhájí to ani možnost statistik přístupů na odkaz, které lze zařídit, pokud bude odkaz mířit např. na servery LDF.
Poskytovatel, nabízející zdarma nějakou službu, má jasný cíl. Nalákat co nejvíce uživatelů a jakmile jich bude mít po pár letech dostatek, může začít službu monetizovat či významně omezit. Takže vám:
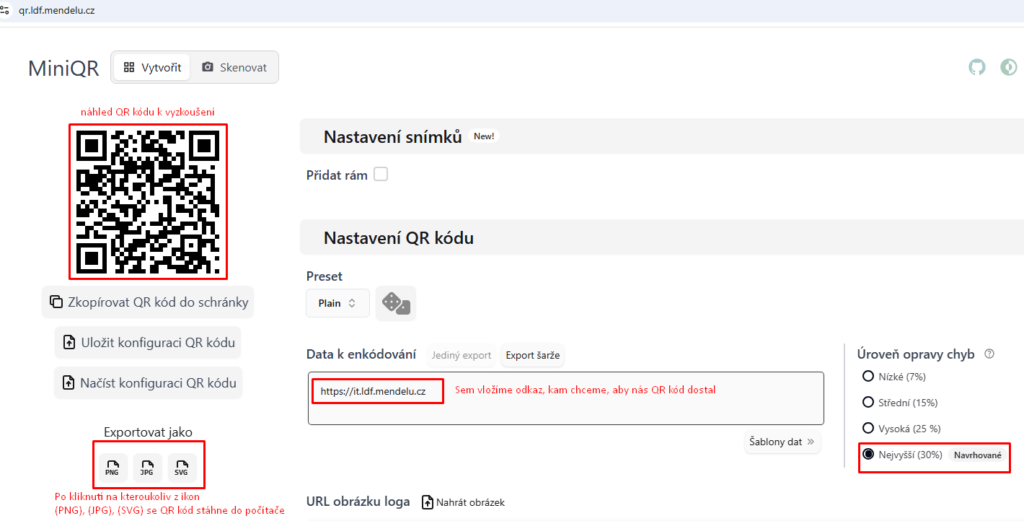
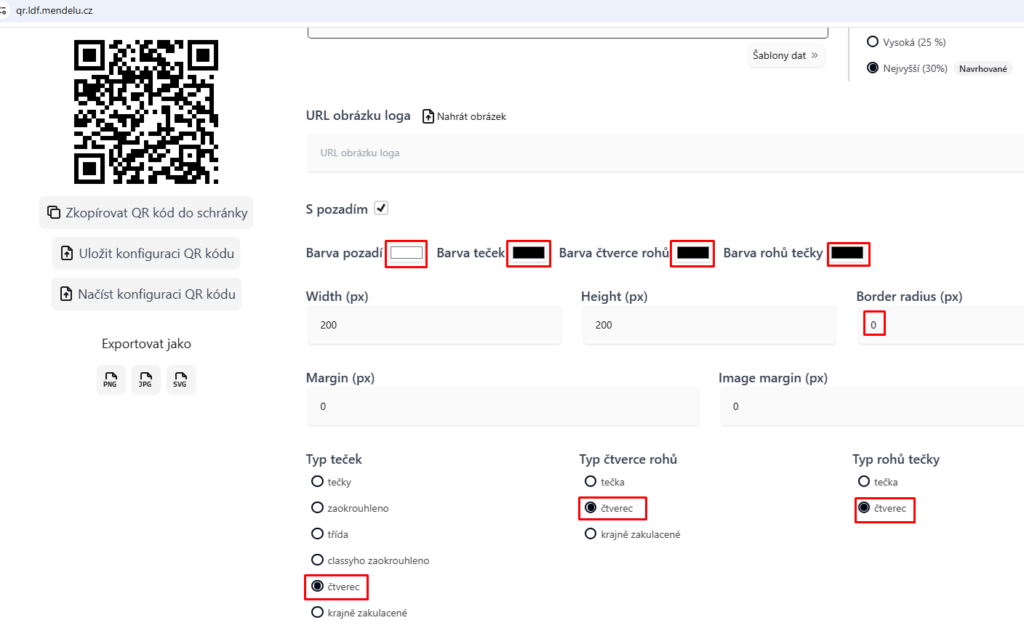
qr.ldf.mendelu.cz, má obří škálu možnosti nastavení vzhledu QR kódu. QR kód může být zakulacený, namísto ze čtverečků se může skládat QR kód z různých koleček, čtverečků s oblými hranami. Doprostřed můžete vložit dokonce obrázek s logem fakulty a rovněž to vždy načte váš telefon v pořádku. Níže přikládám nastavení, abyste získali standardní QR kód, který vidíte v příkladu:
Nelze vyjádřit slovy naši vděčnost za možnost získat dobře zajeté stroje od seznam.cz, jejichž výkon i kapacitu používáme na fakultě na nejrůznější množství nových služeb, projektů i pro zefektivnění práce vědců. Je to již 3 roky od této akce od seznam.cz, pojďme si shrnout to nejdůležitější.
Díky serverům od seznam.cz vzniklo několik bakalářských prací, zabývajících se přípravou na směrnici NIS2, bezpečností, disaster-recovery plány, zálohováním a dalšími přidruženými tématy souvisejících s nejmodernějšími trendy v IT.
Bylo to na hardwaru od seznam.cz, kde jsme zprovoznili 18.4. 2024 první procesorem poháněný jazykový model. První dotaz na testovacím open-source 70 B modelu trval s odpovědí 10 minut, spotřeboval cca 217 GB RAM v peaku a jeho odpověď byla stejně špatná, jako byla naše radost z toho, že to funguje. Ale v rámci RnD to byl nezbytný krok, který bylo nutné udělat správným směrem. Dnes provozujeme 4B a 7B modely a zjišťujeme, že nám to bohatě stačí a odpověď trvá do 30 vteřin s rychlostí 12 tokenů za vteřinu.
Se zmenšením kvót úložišť pro univerzitní pracovníky i studenty, bylo nutné vyřešit velmi palčivý problém. Kam rychle nahrát kapacitu 1000GB za každého zaměstnance, která se jedním oznámením od Microsoftu zmenšila na 100GB? Díky diskovým polím od seznam.cz ve vysoké redundanci to bylo možné zvládnout.
Kolegové mě kontaktovali s možností několika desítek až stovek tisíc fotek z fotopastí, reagujících na pohyb. V první fázi nebylo kam data ukládat. Nyní máme k dispozici disková pole od seznam.cz a kolegům jsem napsal automatizační skripty, které jim dle potřeby jejich fotky zkomprimují bez poznatelné ztráty kvality na cca 34% původní velikosti, stačí jen data nahrát do správného adresáře a servery se o vše postarají automaticky a nabídnou jim původní i zkomprimované fotky k porovnání.
Další vědci fakulty se nejen v rámci projektu Phytophthora věnují porovnávání DNA rostlin/dřevin kvůli dědičným vadám. Z pohledu správy serverů je zajímavé vidět paměťovou i procesorovou náročnost porovnávání „každý s každým“ vzorkem. Soubory DNA jsou roztříděné do 4GB bloků. Operace, která by na notebooku vědci trvala zhruba 3 týdny až měsíc a vzala si ze SWAPu zhruba 250 – 350GB paměti, je na serverech od seznam.cz zpracována během 8 – 20 hodin, podle náročnosti výpočtů. Vědcům se tedy masivně zkrátila doba, kdy se dozvěděli výsledky jejich vědecké práce. Z IT pohledu je zajímavé sledovat grafy takových serverů, kde jsou nárazově vytížena všechna jádra a zaplnění RAM se zvedne z jednotek GB na 350 GB. Pokud mají ti stejní vědci, kteří do té doby počítali jednu úlohu 3 týdny v kuse, najednou k dispozici takových strojů několik, jejich práce ze značně zefektivnila, výsledky jejich práce jsou díky tomu dříve a mají prostor pro opakovaná měření i opakované výpočty, což opět vede ke zkvalitnění výzkumu.
V prosinci 2025 jsem porovnával kompresní algoritmy a při použití LZMA2 s velikostí slovníku 3840MB, velikostí slova 273 a využití 2 jader je paměťová náročnost na zabalení cca 39 GB RAM. Při kompresi na 8 až 10 jader procesoru je spotřebováno cca 350GB RAM pro zabalení a operace může trvat i desítky hodin nad větším množství dat. Přesto je tohle metoda, která nám pomůže získat to, čeho máme nejméně – volné skladovací kapacity pro skladování vědeckých dat i záloh. Servery od seznam.cz nám proto velmi pomáhají nejen se skladováním dat, ale i s jejich kompresí, která není na běžných počítačích při takto velkých kompresních slovnících zvládnutelné.
Na hardwaru v clusterech od seznam.cz nám běží online služby pracující s akustickou tomografií stromů v rámci https://tomotree.mendelu.cz
Na vzniku tohoto projektu se podílelo více ústavů a stejně jako v případě všech dalších projektů a aktivit je mi velkou ctí, že mohu kolegům zajistit odpovídající výpočetní podmínky.
Ze serverů od seznam.cz máme poskládáno několik Proxmox Clusterů podle jejich využití, běží nám na nich i kubernetes clustery. Dříve nebylo vůbec možné uvažovat nad vývojovým a testovacím prostředím, protože jsme neměli dostatečné množství serverů, ani volné kapacity. To vše je nyní možné díky serverům od seznam.cz. Na devových clusterech dostávají svou příležitost prohloubit své zkušenosti nejen bakalanti, ale i praktikanti.
Veškerou techniku od seznam.cz používáme od provozu projektových služeb, přes fakultní i výukové služby. Drtivá většina služeb jsou open-source, kromě tiskových serverů a licenčních serverů komerčních řešení.
Pro lepší přehled na strojích od seznam.cz nám běží 75% licenčních serverů, 90% produkce, 80% výuky, 100% všech clusterů, 100% výpočetních úloh a 90% všech skladovacích kapacit.
Na stroje je přes jejich stáří z pohledu správy vcelku spolehnutí a jsme s jejich správou i provozem velmi spokojeni.
Během posledních 3 let jsme se setkali v podstatě jen s drobnostmi. V zásadě šlo celkem do 15 vadných 750W zdrojů zn. Dell, cca 4 raid baterie Dell, v celé infrastruktuře měníme cca do 20 vadných disků ročně, což jsou finančně velmi příznivé statistiky. Při poslední návštěvě datacentra v lednu byly vyměněny 2x 2,5″ disky a 5x 3,5″ HDD. (všechno dell)
V kombinaci s RAID 6 +1 global hotspare diskem jsme se zatím nesetkali s nutností řešit disaster recovery. Když už je řeč o Disaster-recovery, tak v rámci bakalářské práce studentů máme již zpracované jak plány, tak i disaster recovery scénáře vyzkoušené. Opět díky serverům seznam.cz, které jsme mohli pro tyto účely vyhradit. Do té doby jsme vůbec neměli hardware, který bychom mohli na cokoliv, mimo základních služeb vyhradit.
Díky tomu, že máme konečně „na čem“, máme možnost mít Dev prostředí, na kterém zkoušíme nové technologie, mezi které můžeme zařadit i např. open-source technologii Wazuh, na kterou vznikla bakalářská práce, mimochodem oceněná cenou děkana PEF za mimořádný přínos.
Závěrem bych rád podotkl, že jsme otevřeni dlouhodobým příležitostem, každá technika stárne a je nutné ji postupem času obměnit za novější. Jsem přesvděčen, že pokud se objeví jakákoliv příležitost v budoucnu, pro další obměnu fakultní techniky, s nadšením jakoukoliv podobnou příležitost vítáme.
Je mi velkou ctí oznámit, že díky vyřazeným, avšak stále výkonným serverům od Seznam.cz můžeme výrazně zefektivnit práci našich vědeckých pracovníků. Tito odborníci sbírají data z fotopastí v lesích a následně je analyzují pro své výzkumy. Možná se to zdá jako banalita, ale sesbírat desítky terabajtů dat ze stovek různých fotopastí a kamer připevněných na divoká prasata je náročný úkol. Tyto obrovské objemy dat je nutné nejen bezpečně skladovat, ale také efektivně zpracovat, aby si zachovaly svou informační hodnotu a zároveň zabíraly méně místa na diskových polích.
Proto jsem vyvinul automatizační nástroj pro hromadnou kompresi fotografií a dat, který běží na našich serverech přes noc. Vědci tak mohou během dne nahrát i několik terabajtů fotografií, které jsou poté automaticky zpracovány přes noc. Ráno pak mají k dispozici optimalizovaná data připravená k další analýze.
Díky pečlivému výběru kompresních algoritmů se mi podařilo snížit velikost dat v průměru o 62,9 % – 65,7%, a to bez viditelné ztráty kvality. Systém je navíc kompletně automatizovaný a nevyžaduje žádný zásah ze strany vědců. Ti jednoduše nahrají svá data a nejpozději druhý den mají k dispozici jejich komprimovanou verzi.
Kompresní proces je vysoce efektivní – data jsou shromažďována do fronty a zpracovávána současně až 24 procesorovými vlákny. Naše servery, osazené procesory s TDP 60 W, zvládají tento úkol s vysokou efektivitou a nízkou spotřebou energie.
Tento projekt je skvělým příkladem toho, jak lze efektivně využít zdánlivě zastaralý hardware k podpoře vědeckého výzkumu. Jsem přesvědčen, že v budoucnu dokáži tento systém ještě zdokonalit a nabídnout vědcům ještě lepší podmínky pro jejich práci.
S programem datoles si v univerzitní síti vědci připojí datové úložiště k PC, ze kterého budou nahrávat fotografie:
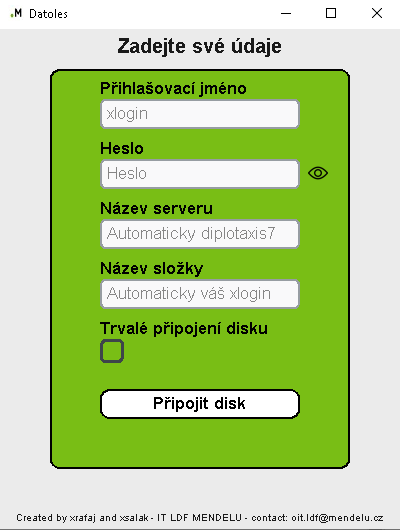
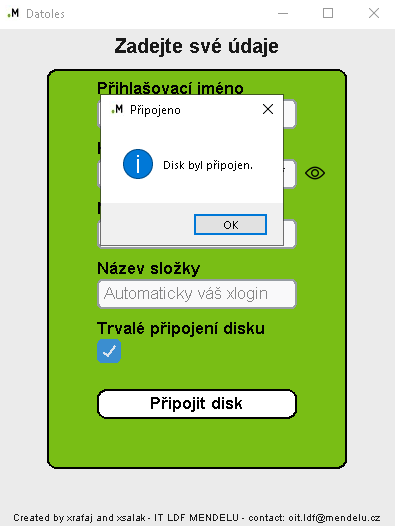
V Tento počítač pak už uvidíte síťový disk:
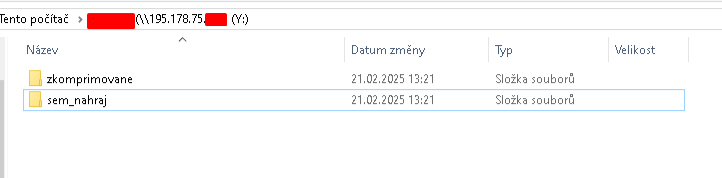
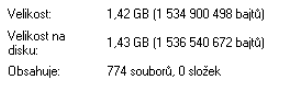
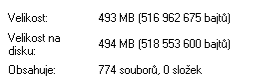
ze 1443 MB server dokázal hromadně zkomprimovat data z fotopastí na 494 MB.
Součástí řešení budou přírůstkové zálohy na další stroje pro dlouhodobé skladování dat. Zatím v přípravě.
Nyní však již funguje replikace veškerých dat na druhé diskové pole na jiném stroji.
Momentálně vás budou všichni nahánět s tím, ať si zaplatíte kurzy školení a používání AI.
To stojí peníze navíc a u jednodenního školení vám pak mohou chybět základní znalosti o problematice.
Zdravím tímto autory, odvedli skvělý kus práce a sdílím tento odkaz, pokud chcete poznat od základů, až po pokročilější prompting oproti AI:
https://aipe.cz/docs/category/-z%C3%A1klady